Why AI defaults to Electron
An AI built me an SSH terminal in five minutes. It lagged. The real question wasn't 'why' — it was 'why did it pick Electron in the first place.
// body
I asked an AI to build me an SSH terminal. Simple stuff — a connection field, an output window, plus a small notes panel on the side. Five minutes later, I had a program. It lagged.
Then came the question — why.
Then came a more interesting question — why did the AI default to Electron in the first place.
What I wanted and why
The idea was small. When you juggle a bunch of projects, everything ends up in your head. You're focused, you SSH into a server, you do a thing, you make a mental note — and a week later you can't remember which server, which folder, which decision. Or you create yet another stray notes.txt somewhere on disk and never find it again.
So: terminal plus notes in one interface. Notes tied to a specific server. Open SSH, see your notes for that box right there. Done.
I described this to the AI. It built it. And the moment I opened the SSH tunnel, the UI started to lag. Two buttons. Opening the output window — slow. I'm sitting there asking myself if I we with AI wrote bad code, if I misconfigured something, if my machine is the problem.
I ask the AI: why is the output window lagging?
The reply was disarmingly honest: "Because it's a browser."
Not "you have a bug." Not "let's profile this." Just — it's a browser. I wanted a program, and I got a browser pretending to be a program.
I push back. "Okay, but I didn't want a browser. I wanted a desktop app." And the AI says: "If you don't like the performance, you can use Tauri + Rust."
So here's the question that started this whole post: if the model knows Tauri + Rust is better — not just better, but optimized out of the box, smaller binary, no lag — why didn't it pick that in the first place?
The answer the model gave me was: "Because Electron is what most people use. They don't debug their software. They don't optimize."
Why Electron is the median
This is the part worth pausing on, because it explains a lot.
Every LLM is, at its core, a language model. It was trained on tens of millions of projects, articles, Stack Overflow threads, GitHub repos. In that training data, desktop app overwhelmingly equals Electron. Slack is Electron. Discord is Electron. VS Code, Notion, Figma desktop, 1Password, GitHub Desktop — Electron. The last ten years of "let's ship a cross-platform desktop app" defaulted to wrapping a browser. So the corpus is saturated with Electron.
Tauri is younger. There are fewer Tauri projects in the wild, fewer tutorials, fewer Stack Overflow answers. In the model's training distribution, Tauri is the minority.
So when you don't specify — when you just say "build me a desktop app" — the model returns the median. And the median, today, is Electron.
This isn't laziness on the model's part. It's the math of how these things work. They're not picking the best tool — they're picking the most representative tool. Best ≠ representative.
The catch is that "representative" doesn't mean good. It means common. Common got us 150MB Slack clients sitting in RAM doing nothing.
The numbers
For my actual project — SENU, the terminal I ended up building — the difference is concrete.
Tauri 2 + Rust build: ~5 MB. Equivalent Electron + React build: ~150 MB.
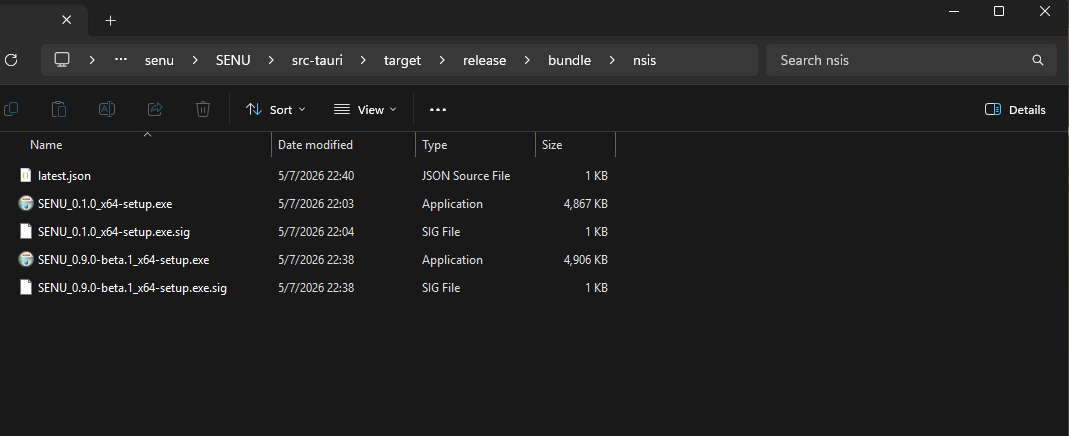
That's not a comfort difference. That's the difference between "I'll install this on the work server with 4GB RAM" and "no thanks." It's the difference between something that respects the machine it runs on, and something that assumes infinite resources.
RAM usage tells the same story. Idle Electron app — 150-300MB easy. Tauri idle — closer to 30-50MB. Memory isn't free. It's just hidden behind hardware that got cheap.
Two paths after that
When you build with AI, you end up on one of two paths.
Path one: the AI gives you what you asked for. You ship it. You're proud — you built a thing. The thing works. The fact that it lags, eats RAM, ships as 200MB, takes 3 seconds to open — it works. You don't look closer.
Path two: the AI gives you what you asked for, and you say no, this isn't it. And then the real work starts. You explain what's wrong. You explain it again because the model didn't understand the first time. You debug. You profile. You point at things. You say "this function is fine but it's being called 300 times per second, fix the calling pattern, not the function." You make 87 small corrections over three months. The AI doesn't see what's broken — it sees only what you point at.
Somewhere in those three months, you stop being just a person who asked for a thing. You become the architect, the tester, the project manager, and the QA. Because the AI doesn't know what you see in your head. It just writes code. You wanted a program — here's a program. Yes, it lags. Yes, it eats memory. But hey, it works.
What I actually learned
This isn't a complaint about AI. It's a description of the profession.
People who expect AI to replace engineering work didn't understand what engineering work was. Writing code was always the smallest part. The big parts — deciding what to build, picking the trade-offs, knowing why something is slow, knowing whether "slow" even matters here, knowing when to throw something away — that's engineering. AI took over the typing. Everything else is still on you.
So when someone tells me "the AI wrote your terminal, not you" — sure. The AI typed faster than I would have. But the AI didn't pick Tauri over Electron. The AI didn't know that 150MB matters. The AI didn't sit through three months of "no, that's not it." That part was me.
And if AI-assisted development feels easy from the outside, here's the honest test: try building something non-trivial with AI and shipping it as a product people use. Not a demo. A thing that has to keep working when conditions change. Then we'll talk.